Enterprise AI Access.
Zero Public Internet.
Production-grade LLM access through managed cloud services, dedicated GPU clusters, or on-premise hardware. Private networking, per-user attribution, full audit logging, and cost controls. Every API call accounted for. No client data exposed.
Cloud · GPU · On-Prem
API Call Audit Coverage
Public Internet Exposure
To Production
Managed Cloud
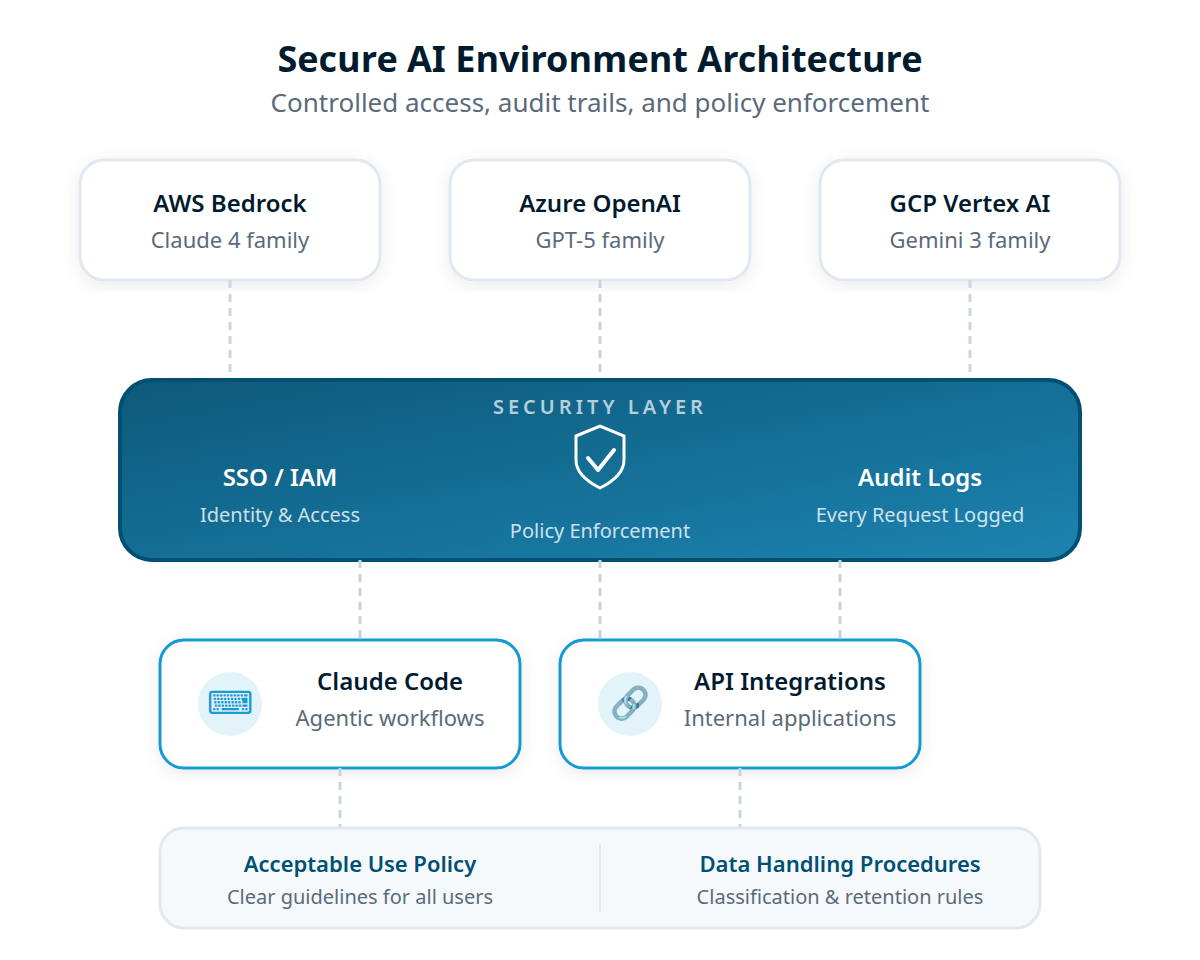
Three Clouds. One Security Standard.
For organizations using managed AI services, your existing cloud footprint determines the platform. We deploy to all three with the same security baseline: private networking, federated identity, and complete audit trails.
AWS Bedrock
Claude, Llama, Mistral, and other models through Amazon's managed service. The most mature enterprise AI platform with deep IAM integration.
- VPC Interface Endpoints (PrivateLink)
- IAM roles with OIDC federation
- CloudTrail + model invocation logging
- Application inference profiles for cost attribution
Azure OpenAI Service
GPT, o-series, and other models through Microsoft's enterprise platform. Native integration with Entra ID and the Microsoft compliance ecosystem.
- Private Endpoints with VNet integration
- Entra ID (Azure AD) with managed identities
- Azure Monitor + diagnostic logging
- Provisioned throughput units for cost control
GCP Vertex AI
Gemini and other models through Google Cloud. Strong data residency controls and native Google Workspace integration.
- Private Service Connect endpoints
- VPC Service Controls with access perimeters
- Cloud Audit Logs + BigQuery analytics
- Regional model deployment for data residency
Dedicated Hardware
Own Your Compute. Control Your Costs.
Managed cloud APIs charge per token. At scale, dedicated GPUs can cut inference costs by 60–80% while giving you full control over data residency and model selection. We design and deploy GPU infrastructure whether you colocate, rent, or buy.
GPU Cloud Operators
Dedicated GPU clusters from operators like Lambda Labs, CoreWeave, or Crusoe Energy. Bare-metal performance with cloud-like provisioning. No per-token pricing.
- H100/H200/B200 GPU clusters on demand
- Flat-rate pricing vs. per-token cloud APIs
- Run any open-weight model (Llama, Mistral, Qwen)
- Scale up or down without long-term commitments
On-Premise Deployment
For organizations that require data to never leave their physical premises. We spec, configure, and deploy GPU servers in your data center or colocation facility.
- Complete air-gap capability
- Hardware spec and vendor selection
- vLLM, TGI, or SGLang inference stack
- Meets ITAR, FedRAMP, and CJIS requirements
Hybrid Architecture
Most organizations benefit from a mix. Route high-volume, predictable workloads to dedicated GPUs. Use cloud APIs for bursty demand or frontier models not yet available as open weights.
- Intelligent routing by workload type
- Unified API layer across all backends
- Automatic failover between providers
- Optimize cost vs. latency vs. capability
Security
Network Isolation by Default
Every environment we deploy uses private networking. API traffic between your developers and the model provider never touches the public internet. VPC Interface Endpoints (AWS), Private Endpoints (Azure), or Private Service Connect (GCP) create direct, encrypted connections within your cloud provider's backbone.
We enforce this at the network level with security groups, service control policies, and organization policies that deny any model invocation outside the private endpoint. The result: no data exfiltration path exists, even if a tool or user is compromised.
Private networking only
VPC PrivateLink, Private Endpoints, or Private Service Connect. Service control policies deny model invocations outside private endpoints.
Federated identity
SSO via OIDC federation with your existing identity provider. Per-user IAM roles, not shared API keys. Every request attributed to a specific person.
Complete audit trail
Every API request logged through CloudTrail, Azure Monitor, or Cloud Audit Logs. Model invocation logging captures prompts and responses for compliance review.
Cost Control
Every Dollar Attributed. No Surprise Bills.
65% of IT leaders report unexpected charges from consumption-based AI pricing. Actual costs exceed estimates by 30–50% on average. We design cost controls into the infrastructure from day one, not as an afterthought.
Per-team inference profiles, rate limits, usage dashboards, and budget alerts ensure you always know what you are spending, who is spending it, and on what models. We also configure prompt caching and model selection strategies that reduce costs without sacrificing quality.
Per-team cost attribution
Application inference profiles (AWS) or deployment-level tracking (Azure/GCP) assign every API call to a team, project, or cost center.
Rate limits and budget alerts
Per-user and per-team rate limits prevent runaway usage. Budget alerts notify stakeholders before thresholds are reached.
Usage dashboards
Real-time visibility into token consumption, model usage, cost trends, and user activity. Exportable for internal reporting and chargeback.
Complete Coverage
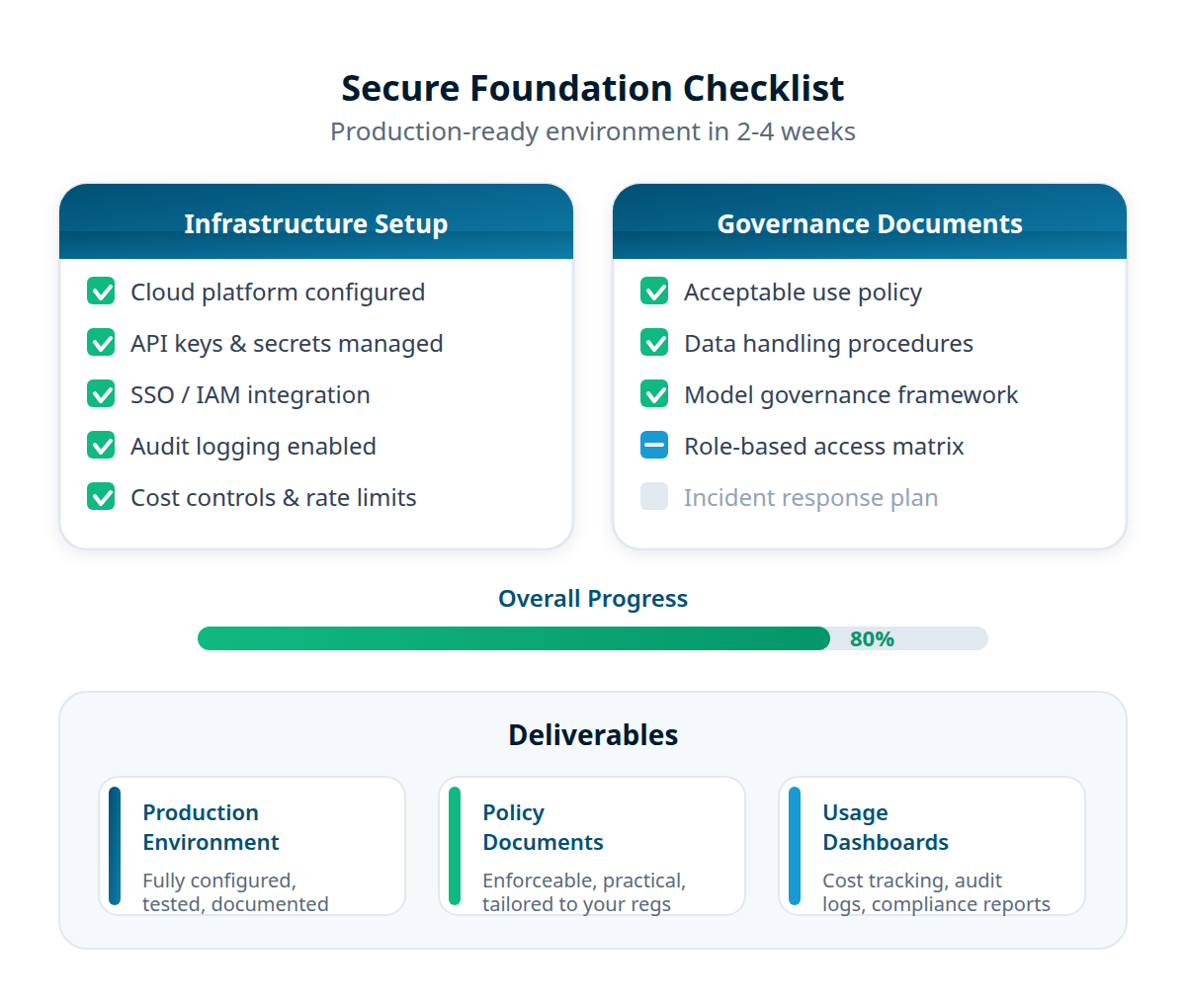
Infrastructure Is One Piece of the Puzzle
Secure infrastructure needs governance policies and trained teams to deliver value.
Acceptable use policies, data classification, and compliance documentation that define what your infrastructure enforces. See AI Governance →
Deploy Claude Code, Codex CLI, and Gemini CLI on your secure infrastructure with hands-on training for your teams. See Agentic Enablement →
Vendor-neutral guidance on which platforms, models, and architectures fit your requirements. See Strategic Advisory →
Why 273 Ventures
We Run This Infrastructure Ourselves
Production experience
Kelvin Agentic OS and Kelvin Intelligence run on the same cloud infrastructure patterns we deploy for clients. We know what breaks and how to prevent it. See our guide to deploying Claude Code safely for an example of our approach.
Cloud and bare metal
We deploy across AWS, Azure, GCP, GPU cloud operators, and on-premise hardware. We run inference on our own GPU clusters and know the operational realities of each option.
Security-first architecture
Private networking, federated identity, and audit logging are not add-ons. They are the baseline. Every environment we build starts with zero public internet exposure.
Get Started
Design Your Secure AI Environment
Tell us your cloud platform, compliance requirements, and team size. We design and deploy a production-ready environment in 2–4 weeks.
Stay ahead of AI in professional services.
Industry insights, market shifts, and what we're building — delivered monthly.
We won't send you spam. Unsubscribe at any time.