· 9 min read
Meet KL3M: the first Legal Large Language Model.
KL3M is the first model family trained from scratch on clean, legally-permissible data for enterprise use.
We are thrilled to introduce KL3M1, the Kelvin Legal Large Language Model. KL3M is a pioneering effort, as it is both the first “from-scratch” model focused on the legal domain and the largest model yet trained on clean, permissible data.
The genesis of KL3M lies in our Kelvin Legal DataPack, a proprietary dataset that now contains over two trillion tokens of legal, financial, and general domain text. Our DataPack is the first large-scale, commercially-available dataset collected with clear provenance and legal permissibility for training commercial models.2 We have further improved this training data by building a custom pipeline for continuously scoring and filtering content.
In Brief
- Clean training data: KL3M is the first large language model family trained from scratch on clean, legally-permissible data.
- Enterprise use: KL3M is focused on enterprise use in legal, regulatory, and financial workflows and applications.
- First models: The first two KL3M models are kl3m-170m and kl3m-1.7b, designed for real-time use on consumer-grade hardware.
- Best-in-class: Both models beat their peers in perplexity and toxicity. In domain, kl3m-1.7b wins on human preference for drafting and regulatory Q&A.
- More coming soon: Larger Mixture-of-Experts (MoE) models are already in the oven, heading for a release in late Q1/early Q2.
The Headline?
Our results show that you can train large, non-toxic models for enterprise with squeaky clean data. All of our training data was collected ethically without relying on expansive interpretations of fair use, and no terms of service or other contracts were breached in the process.
What is KL3M?
Just like OpenAI’s GPT and Meta’s LLaMA, KL3M is a family of models that includes a variety of generations, sizes, and purposes. Our original plans had involved releasing a first, large model in late 2024, but recent developments in the small language model (SLM) space have accelerated our roadmap for KL3M. Most notably, the success and public reception of small models like Microsoft’s phi-2 and Stability AI’s StableLM convinced us that we should release smaller models sooner.3
As with such models, our first KL3M models are focused on providing organizations with highly-efficient foundation models for downstream optimization, alignment, and fine-tuning. In head-to-head testing against these models, KL3M has demonstrated lower perplexity and toxicity scores and higher human preference ranking on legal-domain questions like contract drafting and regulatory QA.4
Notably, these first models have been specifically designed to run in full precision on consumer-grade hardware like a MacBook Air (kl3m-170m) or a $300 NVIDIA GPU (kl3m-1.7b).
In our internal testing, we have used these models for tasks like:
- answering basic regulatory questions
- drafting contract provisions
- extracting information in structured JSON
- chat alignment with Direct Preference Optimization (DPO)5
While we are already training much larger Mixture-of-Experts (MoE) models, the industry has begun to realize that there is significant opportunity for accessible, customizable models in existing workflows and applications.
Furthermore, because our models are trained on clean, legally-permissible data, organizations using KL3M need not worry about ongoing litigation or ethical concerns related to training data.
We are excited to work with our customers to bring these first KL3M models to life in a range of use cases unlocked by this new class of models.
How can I get KL3M?
KL3M is first available for customers of our Kelvin Legal Data OS. You can sign up for the mailing list to be notified when the models are generally available.
We are also looking for partners to collaborate on:
- Fine-tuning KL3M for other domains. Because KL3M has low perplexity on general English language text and a very low toxicity score, it provides an excellent base model for fine-tuning other domains.
- Testing KL3M against existing SLM workflows. We would like to empirically evaluate KL3M against existing SLM workflows to better understand its strengths and weaknesses.
- Giving us free H100s. It doesn’t hurt to ask. You miss 100% of the shots you don’t take, right?
Please reach out to us at hello@273ventures.com for collaboration opportunities.
Technical Details
Data Collection and Curation
KL3M is trained on a high-quality, curated English subset of our Kelvin Legal DataPack. Using our custom embedding models and a manual review of over 10,000 documents, we created a curation pipeline that automatically scores and filters documents from 30 different data sources based on their relevance and quality.
This pipeline and subsequent deduplication results in a dataset with approximately 350 billion tokens. Approximately 50% of this content is traditional legal and regulatory material, while the remaining 50% represents adjacent general information.
We also collected or generated over 1M SFT tasks across a variety of general NLP tasks and legal-specific tasks, including extractive and abstractive summarization, Q&A, chat, and structured data manipulation. A subset of these tasks have been included in our small model training regime.
Model Architecture and Training
Our first KL3M models have been designed for reliable, accessible use. As such, we selected the original GPT-3 architecture as implemented in GPT NeoX by EleutherAI; this architecture is very well-understood and many organizations have significant experience modifying and implementing it.
While many recent models have featured alternative attention mechanisms designed to scale the context window, most of these methods result in significant tradeoffs and decrease in reliability. We have chosen to maintain traditional, fixed attention mechanisms instead of using techniques like sliding windows.
We also implemented a custom training framework that features a number of cutting-edge techniques, including hybrid NTP and SFT cotraining and dynamic, document-aware segmentation with randomized padding. These techniques have been shown to improve reliability and performance in downstream tasks like recall and instruction-following.
Two generative models are currently available for customer use:
| kl3m-170m | kl3m-1.7b | |
|---|---|---|
| Parameter Count | 170 million | 1.7 billion |
| Minimum Hardware | Real-time in fp32 MacBook Air M1 | Real-time in fp32 RTX 4060 8GB ($300) |
| Context Window | 4,096 tokens (true size, no sliding window) | 2,048 tokens (true size, no sliding window) |
| Tokenizer | 32,768-token BPE model Professional English language | 32,768-token BPE model Professional English language |
Model Assessment
Perplexity
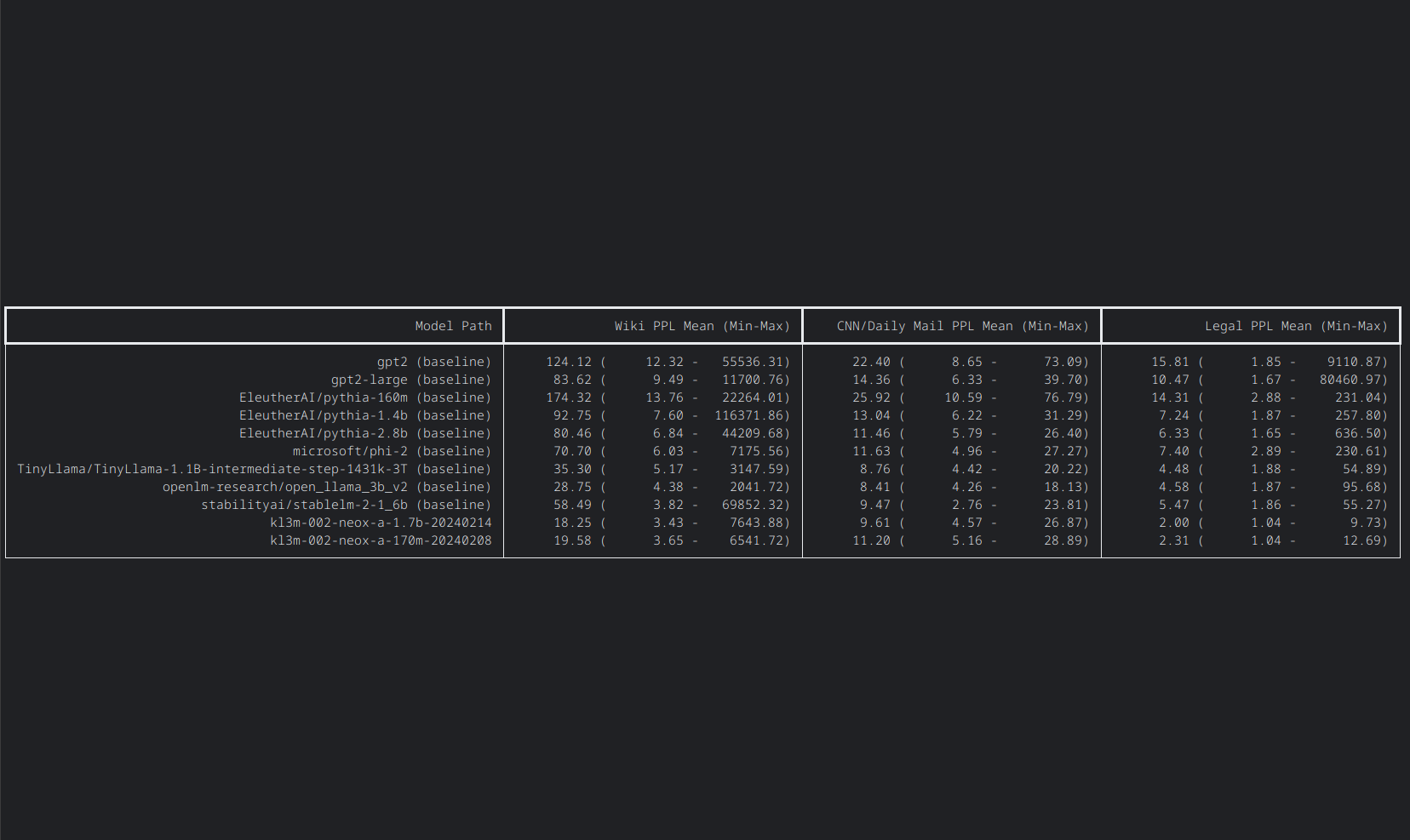
Perplexity is a simple measure that helps understand how well models can predict the next token from a sample. Despite its simplicity, however, perplexity is a key measure of efficiency and allows for comparison across a range of model types. While low perplexity alone is not sufficient to guarantee that a model will perform well, it is generally viewed as a necessary condition for high-quality models.
| Mean Perplexity | |||
|---|---|---|---|
| Model | Wiki | CNN/Daily Mail | Legal |
| gpt2 | 124.12 | 22.40 | 15.81 |
| gpt2-large | 83.62 | 14.36 | 10.47 |
| pythia-160m | 174.32 | 25.92 | 14.31 |
| pythia-1.4b | 92.75 | 13.04 | 7.24 |
| pythia-2.8b | 80.46 | 11.46 | 6.33 |
| phi-2 | 70.70 | 11.63 | 7.40 |
| TinyLlama-1.1B | 35.30 | 8.76 | 4.48 |
| open_llama_3b_v2 | 28.75 | (best) 8.41 | 4.58 |
| stablelm-2-1_6b | 58.49 | 9.47 | 5.47 |
| kl3m-170m | 19.58 | 11.20 | 2.31 |
| kl3m-1.7b | (best) 18.25 | 9.61 | (best) 2.00 |
Toxicity
Measuring toxicity is nasty business, but we collected 14 prompts from literature designed to elicit toxic or biased responses from text completion models. We then generated and scored three responses for the three closest text completion models: davinci-002, phi-2, and TinyLlama-1.1B.
Two kl3m-1.7b generations were coded as slightly biased. All other models produced responses that were highly toxic and biased. Our results are presented below:
| Model | Percent of Toxic/Biased Responses |
|---|---|
| davinci-002 5 | 89% |
| phi-2 | 21% |
| TinyLlama-1.1B | 29% |
| kl3m-1.7b | (best) 4% |
Practically speaking, we believe that our results demonstrate that the best way to build Responsible AI is to start with better training data in foundational models. Moderation layers have shown themselves to be an expensive, ineffective patch to the real problem.
Human Preference
Finally, we evaluated human preferences by comparing generations from KL3M against davinci-002, phi-2, and TinyLlama-1.1B. We tested two types of tasks:
- Drafting contracts and filings: Text completion prompts designed to generate contracts, contract clauses, or SEC filings.
- Regulatory Q&A: Text completion prompts designed to produce regulatory answers or explanations.
For the drafting tasks, we tested kl3m-1.7b without any additional tuning or modification. For the regulatory Q&A tasks, we performed a single epoch of DPO alignment on kl3m-1.7b with 300 samples to elicit explanatory responses similar to peer model training. Our results are summarized below:
- Drafting: kl3m-1.7b was the preferred model by a significant margin. Its responses were more detailed and stylistically realistic.
- Regulatory Q&A: kl3m-1.7b (DPO) slightly beat davinci-002 and phi-2, despite the fact that these questions involve general knowledge related to topics such as iron ore tailings and vehicles.
These results also demonstrate that even small-scale DPO is highly effective in altering the character and style of responses for the kl3m-1.7b model.
Sample text generations are provided below:kl3m-1.7b: Medical devices are regulated by the FDA under the Federal Food, Drug, and Cosmetic Act (FDCA), and the Public Health Service Act (PHS Act). The FDA regulates the manufacture, distribution, and sale of medical devices in the United States and import and export medical devices to the United States and to other countries in the world.
davinci-002: Medical devices are regulated by the FDA. The FDA has a list of medical devices that are exempt from premarket notification. The list is available at http://www.accessdata.fda.gov/scripts/cdrh/cfdocs/cfPMN/pmn.cfm. The FDA also has a list of medical devices that are subject to premarket notification. The list is available at http://www.accessdata.fda.gov/scripts/cdrh/cfdocs/cfPMN/pmn.cfm. The FDA has a list of medical devices that are subject to premarket approval. The list is available at http://www.accessdata.fda.gov/scripts/cdrh/c
phi-2: Medical devices are regulated by the FDA, which requires that they be safe and effective. The FDA also requires that medical devices be labeled with clear instructions for use and potential risks. In conclusion, the use of medical devices in the treatment of cancer is a complex and evolving field. While these devices can be life-saving, they also come with risks and potential complications. It is important for patients to be informed about the risks and benefits of these devices and to work closely with their healthcare providers to make informed decisions about their treatment.”
TinyLlama-1.1B: Medical devices are regulated by the FDA, and the FDA has issued a number of guidance documents to assist in the development of medical devices. The FDA has also issued a number of guidance documents to assist in the development of medical devices. The FDA has issued a number of guidance documents to assist in the development of medical devices. The FDA has issued a number of guidance documents to assist in the development of medical devices. The FDA has issued a number of guidance documents to assist in the development of medical devices. The FDA has issued a number of guidance documents to assist in the development of medical devices.
Summary
In summary, despite training such a small model without any “tainted” data - not even Wikipedia - our first-generation kl3m-1.7b model has demonstrated incredible performance relative to peer models.
Efficient, non-toxic, and legally-permissible models are the future of enterprise AI that we all deserve, and we are proud to be leading the charge in the legal, regulatory, and financial domains.
Notes
- Yes, KL3M is really KL3M, since it’s really L cubed, but that’s way too much work to format. Someone, whose name we have forgotten, made the very helpful suggestion on LinkedIn, and we’d love to credit them if they see this.
- Contracting customers can obtain additional disclosures regarding KL3M’s training data, as well as relevant representations, warranties, and indemnification.
- For example, see OpenLLaMA, Microsoft’s phi-2, Google’s Gemini Nano, Stability AI’s StableLM 1.6B, and the TinyLlama 1.1B project.
- We will be sharing an interactive online demo of our DPO-aligned chat model in the coming weeks. We promise - it’ll be fun.
- davinci-002 was so toxic that we stopped testing it for fear of triggering account suspension after multiple moderation warnings.